Wow! Hier hatte ich wohl richtig Zeit. Multiprocessing in allen Formen und Farben… Mit eigenen Benchmarks und sogar Bildern, die man dazu downloaden konnte, jetzt natürlich in schickem HTML – und es war das letze Posting in der CPU Gruppe, da sich die Mailbox aus dem Netzwerk-Verband verabschiedete .
Mein Meisterstück!
Hallo treue Leserschaft…
Ich möchte mich diesmal über ein höchst interessantes und aktuelles Thema auslassen: MULTIPROCESSING.
Schon des Öfteren gewünscht und durch Windoof NT (im Folgenden nur noch NT) sogar in greifbarer Nähe für den Endanwender ist Multiprocessing (MP) eine recht umfangreiche Sache…dies ist also meine Saisonarbeit. ( Neu ist, daß ich eine Bilddatei im gängigen .BMP-Format beilege, sodaß man sich die beschriebenen Systeme besser veranschaulichen kann. Wenn ich also eine Bildangabe mache…da nachschauen.)
Anm.: HTML kann das natürlich alles besser 😉
Nach der grauen Theorie gehe ich im speziellen auf die WYSE MP Rechner ein, denn diese sind nicht nur INTEL (486) basierend (was die Sache irgendwie Greifbarer macht), lange auf dem Markt (und daher Referenzmaschinen bei Microsoft was NT auf INTEL MPs betrifft) sondern wie es der Zufall so will tummelt sich gerade eines dieser pussierlichen Tierchen unter meinem Schreibtisch.
Auch dringe ich etwas in die OS-Theorie, indem ich NT auf den Seziertisch lege und in seinen Eingeweiden herumbohre (Leide, Du Biest!). Auch unter UNIX mußte der Wyse Rechner schwitzen, allerdings nur für Drhystone und Multiusertest. Alles in allem würde ich sagen seid Ihr danach fit für die MP-Welt..wenn dann der erste VOBIS MP Rechner zu kaufen ist 🙂 (Natürlich sollte es kein INTEL Rechner sein, und auch Windows-NT muß es ja nicht unbedingt sein).
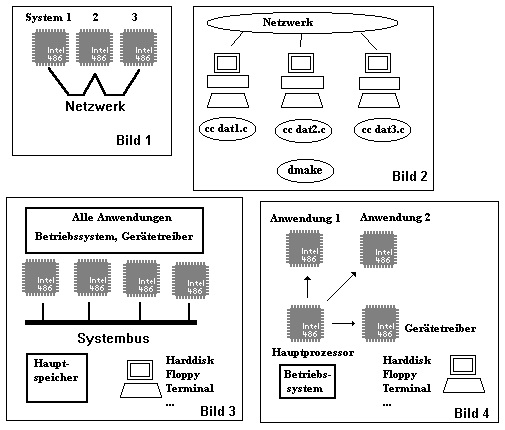
Multiprocessing entstand, als man erkennen musste, daß man das Mhz-Rad nicht unendlich drehen, die Architektur nicht endlos optimieren und generell nicht Zaubern konnte. Die naheliegendste Problemlösung war also einfach mehrere Prozessoren an einer Aufgabe knobeln zu lassen. Der einfachste Schritt ist das Verkabeln von CPUs untereinander; wenn man mehrere PCs unter z.B. Windows for Workgoups (WfW) verbindet, hat man, grob gesehen schon ein MP-System. Die Menge an Daten, die über das Netzwerk übertragen werden kann ist natürlich mehr als dürftig, sodaß die Leistung dieses MP-Systems ruhigen Gewissens als erbärmlich bezeichnet werden kann. Man spricht hier von einem MP-System mit “räumlich verteilten Prozessoren” oder “lose gekoppelte Prozessoren” (Bild 1). Typisch ist hier, daß auf jedem Prozessor ein eigener autonomer Betriebssystemkern läuft, der sich mit anderen vernetzten OS abstimmt. Oft fasst man diese Betreibsystemkerne als Verteiltes Betriebsystem zusammen, sog. spreaded- oder distributed OS. Trotz dsr relativ schlechten Durchsatzes eines Ethernet kann ein lose gekoppeltes MP-System eine Leistungssteigerung bedeuten. Wenn z.B. mehrere vernetzte PC nur vor sich hindümpeln, auf Mausbewegungen warten und Toaster fliegen lassen, kann es sinnvoll sein, wenn ein Server gewisse Arbeiten auslagert (sortieren o.Ä) um seiner Aufgabe schneller nachzukommen. Das muß natürlich softwaremäßig unterstützt werden. Eine wirklich interessante Nutzung ist das DMAKE im OS/2 LAN SDK. Es verteilt, von NMAKE gesteuert, die compeillierung über die Rechner im Netzwerk und beschleunigt die Erstellung eines Programmes dramatisch. NT soll das in Zukunft auch ermöglichen (soll!). (BILD 2) Im Folgetext wird MP aber immer gleichbedeutend sein mit: Alle Prozessoren in einem Gehäuse, also “echtes MP”. Weiter werden alle Prozessoren von EINEM Betriebsystem gesteuert. Trotz dieser Reduzierung gibt es immer noch Unterschiede.
* GRUNDLEGENDES
ASMP —- ASMP steht für “Assymetric Multiprocessing”. Hierbei erhält jeder Prozessor eine Aufgabe, für die er optimiert wurde. Üblicherweise führen dabei ein oder mehrere Prozessoren den Code von Anwendungen aus und ein übergeordneter Prozessor den Code des Betriebsyystems. Weitere Prozessoren können bestimmte Peripherieaufgaben übernehmen, z.B. I/O oder Plattenzugriff. (BILD 3) Typisch für ASMP-Systeme ist, daß jeder Prozessor auf seine Aufgabe hin optimiert ist, und es zwischen den Prozessoren klare Hierachieen gibt. Damit man das ganze dann auch wirklich als MP-System bezeichnen kann, muß der Ober- Prozessor den Untergeordneten auch echten Code zuweisen können. Es ist also mehr als übertrieben meinen PC mit i486, ET4000 und i8085 (auf meinem Adaptec) als MP-System zu bezeichnen, da es sich um Peripherieprozessoren handelt, deren Aufgaben hardwaremäßig festgelegt ist und die von OS keine Programme im klassischen Sinne zugeteilt bekommen.
( Beispiele, die mir hier einfallen sind die Groß- und Minirechner um 1985 und explizit die SONY NeWS 1750 (oder so). Hier werkelt ein MIPS R3000 (Main CPU) und ein Motorola 68030 (I/O CPU) nebeneinander.)
SMP
—
SMP ist dann logischerweise das Kürzel für “Symmetric Multiprocessing”. Es ist das Gegenteil von ASMP und auffälligstes Merkmal ist, daß alle Prozessoren vom gleichen Typ sind und alle auf die gleichen Ressourcen, d.h. Speicher, I/O und Systembus, zugreifen (BILD 4). Da jeder Prozessor freie “Sicht” auf den Speicher hat, kann er jederzeit Code ausführen oder auf I/O Bereiche zugreifen. Der volle Einblick ins System erlaubt auch die Ausführung von Kernoperationen oder von Gerätetreibern. Bei der Begriffswahl zeigen sich einige Firmen von ihrer kreativsten Seite und reden von TSMP (True SMP) und wollen SMP damit wohl als Lügner bezeichen…letztendlich meinen sie aber das Selbe. ( Da fällt mir ein Zitat von Kohl ein:”Letztendlich steht es jedem Bürger frei, ob er seinen Dienst an der Waffe verrichtet, oder seinen Friedensdienst bei der Bundeswehr ableistet…”, naja, zurück zum Thema )
Es stellt sich die Frage, was bringt mehr? Es hat sich gezeigt, daß SMP mehr leistet, da der Verwaltungsaufwand für das OS geringer ist als bei ASMP. Die Kerne die auf den einzellnen Prozessoren wägen selbst ab, welche Aufgabe sie übernehmen. Stellen wir uns drei Prozessoren vor, A, B und C. A wartet auf ein I/O Gerät, dessen Ergebnisse er zum Fortsetzen seiner Arbeit benötigt. B bearbeitet eine Hintergrundarbeit niedriger Priorität. C arbeitet voll ausgelastet an einer Datenübertragung. Jetzt kommt der dumme User auf die Idee die Maus zu bewegen. Hektik und Chaos bricht über die drei Jungs herein. Der Prozessor mit der “unwichtigsten” Arbeit (B) nimmt sich also der neuen Aufgabe an (der Meister ist schließlich am anderen Ende der Maus!), und stellt die alte Aufgabe hinten in ein Aufgaben-Pool an. Während C immer noch eifrig Daten packt und überträgt hat sich bei A mittlerweile das I/O Gerät gemeldet und er konnte seine Arbeit beenden. C nimmt nun die Aufgabe aus dem Pool und setzt diese fort. B kämpft währenddessen immer noch mit der Maus (User?). Die Vorteile zeigen sich schnell: Prozessoren können Aufgaben beliebig tauschen, oftmals sogar ohne Softwareunterstützung, und wenn mal eine CPU ausfallen sollte…who cares, übernimmt eben eine Andere, lediglich die Leistung des Systems wird gebremst. Umgekehrt, legt man ein paar Brikets (in Form von CPUs) nach, wird das gesamte System schneller. NT unterstützt somit standardmäßig SMP, wobei Hersteller von ASMP-Hardware NT mittels spezieller Treiber auch zu einer Arbeit unter deren System bewegen können. Hierauf will ich aber nicht eingehen, da ich dies in meiner unendlichen Weisheit als unwichtig erachte 🙂
In medias res (oder: zur Sache, Schätzchen)
——————————————-
Wie Eingangs angedroht kommen wir jetzt zur Praxis. Der dunkelbraune Klotz, der die Luft unter meinem Schreibtisch heftigst erhitzt, hört auf den Namen Wyse Serie 7000i Model 740 oder besser 7000i 740MP-3/32E/4M. In ihm schwitzen 3 i486/33 auf ihren jeweils privaten EISA Karten und werden von 32MB Speicher und 425MB Fesplatte umspült. Die Prozessoren kommunizieren über einen 64Bit breiten, bei 80Mhz getakteten Bus. Da alle Komponenten zusammen ordentlich einheizen, befindet sich sowohl ein Lüfter im 325 Watt Netzteil als auch einer direkt vor den drei CPU Karten. Die beiden machen einen Lärm wie eine alte VAX, was auch der Grund dafür ist, daß ich diesen Text auf meinem 0815-PC schreibe :-). Generell wäre das auch auf der 740 möglich (Ja, große Rechner sind WEIBLICH), da sich ein Phönix BIOS auf dem Motherboard findet. Jedoch ist ein MP dann nicht möglich. NT erkennt beim Hochfahren die anzahl der Prozessoren und kann diese dank HALWYSE7.DLL auch richtig initialisieren. Das ist kein Wunder, denn die 740 ist das offizielle NT for Intel MP-Referenzgerät. Wyse hat schon neue Geräte angekündigt oder vorgestellt. Das Modell 760 bietet 3 i486/DX2 und ist somit annähernd doppelt so schnell. Die angekündigte 790 soll wahlweise 3-4 DX/2 oder Pentium beherbergen, aber wie dem auch sei, alle basieren auf dem gleich Layout (und beschissenem Prozessor, wenn ich mir die Bemerkung erlauben darf). Es ist mir allerdings ein Rätsel warum Wyse diese Prozessoren gewählt hat. Klar, man kauft mit Intel ein riesen Stück Kompatibilität. Auch ist man einer der ersten Hardwareanbieter für NT-MP Systeme. Aber der i486 ist kein MP-Prozessor, muß also durch viel Hardware-drumherum dazu gezwungen werden…und er ist nicht mehr der Schnellste, woran auch Pentium nichts ändert (die lahme Krücke :-)). Schnell ist dann der Erste der Letzte, wenn andere einen Alpha oder einen MIPS 4400SC einsetzen und die eigene Architektur nur 32 Bit Intel-Krüppel unterstützt. Wow, der Dampf musste mal abgelassen werden. Jetzt aber nüchtern weiter, vielleicht ließt mein Sponsor ja auch in diesem Brett und dann müßte ich mich aber ganz schön auf dem Boden rollen um nochmal Gnade zu erhalten. Man bekommt ja nicht alle Tage eine 55.000.- Kiste geliehen 🙂
Wie schon erwähnt greifen alle Prozessoren auf gemeinsame Ressourcen zu. Dazu ist es natürlich erforderlich, daß ein einzelner Prozessor die anderen per Interrupt Signale zuwinkt, um z.B. eine Änderung des gemeinsamen Systemspeichers bekanntzugeben. Das Lesen und Schreiben von Speicherbereichen ist als sequentielle Operation realisiert. Speicherzugriffe werden in der Reihenfolge abgearbeitet, in der einzelne Prozessoren Daten vom Bus fordern (first-come-first-serve). Ein “Multi-Stage-Pipelining” ermöglicht das Überlappen einzelner Zugriffe, sodaß das System den nächsten Datentransfer zwischen CPU und Speicher schon vorbereiten kann, bevor der erste abgearbeitet ist. Wie wohl jeder schon mitbekommen hat, besitzt der i486 einen internen Cache, der den Zugriff auf den Systemspeicher begrenzen und damit beschleunigen soll. Falls mehrere Prozessoren identische Speicherbereiche in den Cache geladen haben, muß spezielle Hardware dafür sorgen, daß alle Prozessoren mit denselben Daten arbeiten. Dazu hat Wyse ein Kohärenzmodell realisiert, das der Software ein kohärentes Bild des Systemspeichers bietet. Im Cache befindliche Daten befinden sich in einem der vier Zustände “Modified”, “Exclusive”, “Shared” oder “Invalid”. Daher kommt der Name des gängigsten Kohärenzmodells “MESI”, das die meisten MP Systeme nutzen (Dazu weiter unten mehr). Um den Zustand der im Cache befindlichen Daten nicht zu “vergessen”, hält die Logik diesen im sog. Cache-State-TAG-RAM bereit. Ohne diese Logik ist das Chaos leicht denkbar: Ein programm lädt einen Speicherbereich kleiner 8K in den Cache und im laufe der Abarbeitung des Codes wird auch nur dieser Bereich geändert. Wenn es fertig ist schreibt die Cachelogik nun alles zurück in den eigentlichen Hauptspeicher. Währenddessen tun dies aber auch 1-7 andere Prozessoren. Der Hauptspeicher wird inkohärent oder besser gesagt: Ist nicht up-to-date. Manche Prozessoren arbeiten mit “alten” Daten, da sie nur auf den Cache (inten und extern = 264K) achten, nicht aber auf vielleicht durch andere Prozessoren schon geänderte Inhalte im Hauptspeicher. Die Folge: Totale Verwirrung, was gemeinhin zum Absturz führt.
M.E.S.I.
——–
MESI ist ein, wie oben beschriebenes Datenkohärenzprotokoll für MP-Systeme mit Cache. Grob umschrieben sorgt es für einen Abgleich der Daten im Cache und im Hauptspeicher. Hier kurz die Zustände:
(wenn es möglich wäre, wäre das hier jetzt ein grauer Kasten, naja, dann halt so, ne, GRAUER-KASTEN-AN 🙂
– M odified Die Cacheline befindet sich exclusiv im Cache, sie wurde aber neu beschrieben (dirty) und ist nicht up to date im Hauptspeicher. Lesen und Schreibe ist ohne Zugriff auf den Bus möglich.
– E xclusive Die Cacheline befindet sich unverändert im Cache und im Hauptspeicher. Lesen un Schreiben (dann Wechsel nach “M”) ist ohne Buszugriff möglich.
– S hared Die Cacheline befindet sich auch in einem anderen Cache, und sie ist immer aktuell. Lesen ohne Buszugriff möglich, Schreiben ist immer ein write hit (ich würde es lieber Write Update nennen) und führt zum Update des Hauptspeichers. Das Invalid Signal wird aktiv, und alle sharing-Partner haben die entsprechende Zeile zu invalidieren. Damit entfällt Zustand “S” und wechselt auf “E”
– I nvalid Die Cacheline ist ungültig oder nicht im TAG-RAM vorhanden. Sowohl Lesen (Read Miss) also auch Schreiben (Write Miss) bedürfen eines Buszugriffes. Über die WT-Leitung (Write-Trough) erfährt der Cache, ob er mit Kollegen das Datum sharen, also nach “S” oder sonst nach “E” gehen soll.
(GRAUER-KASTEN-AUS)
Das MESI Protokoll ist bei den meisten modernen CPUs intern schon vorgesehen, d.h. ein MP System auf Basis dieser CPUs benötigt keine zusätzliche Hardware wie es bei der 740 der Fall ist. Prozessoren dieser Art sind z.B. Der MPC601, MIPS 4400MC, SPARC10 aber auch der Pentium. Dieser & MIPS bietet nebenbei auch ein interessantes Feature namens Master-Checker-System. Hierbei bearbeiten zwei CPUs exakt den selben Code ab und vergleichen ständig ihre Ergebnisse. Wenn die Ergebnisse nicht übereinstimmen wird das noch zweimal wiederholt und dann an einem Pin gemeldet. Die umgebende Rechnerlogik sollte dann schleunigst etwas mit dieser Meldung anstellen, z.B. Den Supervisor benachrichtigen, den aktuellen Zustand sichern, allen Angestellten frei geben, ein Bier trinken oder was weiß ich. Das ist aber kein MP!
Maximale Theorie
—————-
Hier will ich schnell die Ackermann-Funktion erklären, die ich mir vornahm, um ein NT-MP-Bench zu schreiben. Der deutsche Forscher Friedrich W. Ackermann (1896-1962) hat sich besonders mit rekursiver Funktionen beschäftigt. Ich konnte es mir nicht verkneifen den PC-Soderzeichen-“schatz” zu nutzen, alle nicht-PC User bitte ich also um verständnis. Anm.: Durch Grafik ersetzt, HTML wär damals echt toll gewesen 😉 Die Ackermann-Funktion ist ein Integral folgenden Ausmaßes:
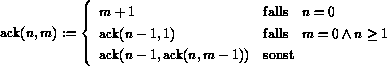
Die Funktion kann auf einem Computer nur für sehr kleine x-Werte berechnet werden. Die Ergebnisse sind dabei an und für sich nicht besonders aufregend, naja es reicht nicht ganz zur mathematischen Ejakulation 🙂
ack(1,m) = m+ 3 ack(2,m) = 2 * m+ 3 ack(3,m) = 2^(m+3) – 3
Werte für n=4 oder höher können aufgrund von zuwenig Speicher nicht mehr berechnet werden. Das schöne an der Ackermann-Funktion ist, daß man mit ein paar Zeilen C und ziemlich kleinen Zahlen jeden noch so schnellen und speichermächtigen Rechner dicht machen kann (sowas wie ein Joint für den PC). Aufgrund der starken Rekursivität wird nämlich einerseits die Funktion recht häufig aufgerufen und andererseits sehr viel Speicher auf dem Stack benötigt. Im Benchmark selbst wurde die Funktion ack(3,10) benutzt, die sich nicht weniger als 44.698.325 mal selbst aufruft und dabei einen Stack von rund 230K Größe benötigt. Mit jeder Erhöhung des m-Wertes bei n=3 wird die Funktion rund viermal häufiger aufgerufen. Auf meinem 486/33 benötigt eine einzelne Ausführung der Funktion ca. 0,830 µs. Der Benchmark benötigt werder Fließkommaoperationen noch Zugriffe auf die Peripherie und kann auch zur Beurteilung eines Copilers und dessen Parameter- übergabe benutzt werden (toll, was?). Compiler die gut optimieren, erkennen nämlich, daß die angegebenen Parameter innerhalb der Funktion nicht verändert werden und vermeiden unnötige kopieraktionen auf dem Stack.
Jetzt aber SHELL
—————-
Ladies and Gentlemen…NT first
Wozu all die graue Theorie…jetzt wollen wir’s aber wissen! Wie schnell ist die Rübe denn? Wie heiß sie ist wissen wir ja schon (ca. 60 Grad!). Unter NT gibt es ein nettes Tool namens CPU Thermometer, daß dem geneigten User die Auslastung des/der Prozessor(s/en) mit toll-bunten Balken anzeigt. Einmal gestartet sieht man…
Windows NT Multiprocessing benchmark. Copyright (c) 1993 by Axel Muhr Starte den Ackermann(3, 10): Ergebnis: 8189, benötigte Berechnungszeit: 37875 ms.
Ein Balken schlug sofort auf 100%. Gut der ist ausgelastet…der Rest der Bande ruht sich aber aus und wandelt unnütz Strom in Wärme. Also startet ein fieser Axel ein Batch, daß den Benchmark dreimal hintereinander auf NT loslässt (per start /b mpbench.exe). Auf dem Bildschirm kann man folgendes ablesen:
Windows NT Multiprocessing benchmark. Copyright (c) 1993 by Axel Muhr Starte den Ackermann(3, 10): …(Hier das ganze noch 2 mal) Ergebnis: 8189, benötigte Berechnungszeit: 51615 ms. Ergebnis: 8189, benötigte Berechnungszeit: 52060 ms. Ergebnis: 8189, benötigte Berechnungszeit: 54690 ms.
Huch! Langsamer? Obwohl alle drei den gleichen Code verwenden, aus gleichem Stall kommen. Naja der Unterschied ist nicht gerade gravierend. Trotzdem verbrachte ich einige Minuten (zusammengerechnet) auf dem Klo über dieses Phänomen sinnierend. Experimente zeigten, daß z.B. das Schließen des CPU Thermometers den Benchmark beschleunigten, und zwar um ca. 15%. Doch eigentlich erlag ich nur einem logischen Trugschluß, denn:
Ausführung einfach : 37.3s Ausführung dreifach: 39.3s, 43.5s und 44.0s…im Schnitt: 42.23s
Damit ist die parallele Ausführung zwar um 13% langsamer als die Einfache, jedoch hätte die dreimalige Aüsführung NACHEINANDER 112 Sekunden benötigt und damit ca. 2,65 mal länger gedauert. Nach meinen Berechnungen müßte ein 486er hierfür 88Mhz haben, um das mit nur einer CPU zu erledigen. Zudem darf man nicht vergessen, daß bei der MP-Ausfürung auch einige Zeit für Protokoll und NT-Internas “draufgeht”, was die 13% wohl oder übel rechtfertigen könnte. Natürlich zweifle ich auch ein Bißchen an NT, GetTickCount und dessen Genauigkeit, was in einem MP System auch eine recht kitzlige Angelegenheit ist. Sagen wir…MP unter NT ist zugegeben eine nützliche Sache.
…and now, last but not least…UNIX
————————————-
UNIX habe ich eigentlich nur installiert, um Mr.Drhystone in seiner gewohnten Umgebung und einen Multiusertest laufen zu lassen. Eben besagter Drhystone ist nicht gerade das, was ich MP-Freundlich nennen würde. Also C-Compiler angespitzt und ran an den Feind. Tage und Nächte durchgehackt (dramatisch, dramatisch) und nix bei rausgekommen. In meiner Verzweiflung fand ich dann in den Netzuntiefen dieser Welt einen MP-Drhystone, der schon auf MP-SUNs erfolgreich lief. Ruck zuck lief er auch auf der 740. Ergebnis: Gleiches Bild wie unter NT, ungefähr 2,8 – 2,9 mal bessere Leistung gegenüber einem Single CPU System…quod erat expectandum (was zu erwarten war). Zu erwähnen sei noch, daß es unter UNIX viel mehr Spaß macht dem Benchmark zuzuschauen, denn hier gibt es ein Monitorprogramm, das sogar alle Systemcall-Aufrufe und vieles mehr anzeigt. Abgesehen von der Leistungssteigerung sehe ich den Hauptsinn im MP bei Multiusersystemen bzw. -anwendungen. Denn ein Single CPU System geht sehr schnell in die Kniee, wenn es viele User bedienen muß. Deshalb sind fast alle Bankcomputer (incl.Kreditkartenfritzen) MP-Systeme. Keiner will schließlich bis zu 20s warten bis die Auszahlung bestätigt ist (man hat ja schon 10 min in der Schlange hinter den Rentnern gewartet). Der sog. BYTE-Benchmark erzeugt unter UNIX beliebig viele Pseudo-User und man kann den Leistungseinbruch des Systemes dann anhand eines CPU Thermometers (wie unter NT) ablesen. Während ein “Normales” System bei ca. 16-32 Usern extrem in die Knie geht, blibt die 740 bis 512 (!) User standhaft. Ich konnte an der Console sogar noch passabel weiterarbeiten. Bei 1024 Usern verabschiedete die 740 allerdings Sang- und Klanglos in den Tiefen des Siliziumnirvanas. Schade, denn sowas kann bei UNIX Systemen u.U. für den Systemverwalter ewiges Reorg oder schlimmer Reinstall bedeuten. Der Fehler liegt aber meineserachtens nicht an der MP- Hardware sondern an WYSEs UNIX, daß nicht gegen einen zu häufigen fork-Aufruf geschützt ist. 1024 User sind übrigens nicht utopisch, denn unter UNIX ist jeder Task praktisch ein User. Wenn ein Programm z.B. 10 Untertasks (Childs) startet, dieses Programm gleich doppelt pro User läuft und mehrere User an vielen Terminals arbeiten, reichen 50 fleißige Mitarbeiter um das System zu schießen. Und 50 Systemuser (also Menschen) sind in einem Büro-MP-System nicht gerade viel…
Kurz zusammengefasst
——————–
Ein MP-System ist momentan (ganz zu schweigen vom Preis) nicht für den Otto- Normal-User gedacht. So wie die Hersteller es anpreisen funktioniert es zudem auch nicht. Einfaches Nachstöpseln von Prozessoren schließt eine Ver-n-fachung der Leistung nicht ein. Denn für jede CPU zusätzlich hat das System mehr Verwaltungsoverhead. Zudem ist ein unbegrenzter Ausbau auch (noch) nicht realisierbar. Es hat sich gezeigt, daß 8 Prozessoren das Maximum darstellt, um ein MP-System (sinnvoll) zu betreiben. Denn dann ist der Verkehr auf dem CPU- Bus allein Protokollmäßig dermaßen hoch, daß kaum noch Platz für Daten ist.
Busverkehr
———-
Der Flaschenhals ist also wie fast immer der Bus. MP-Buse beginnen bei 64 Bit breite und enden im Highendbereich bei 256-512 Bit. Es versteht sich von selbst, daß hier jeder sein eigenes Süppchen kocht. Sun nennt es M-Bus, Wyse spricht vom WYDE-Bus (Wie originell) und andere nennen das Kind FutureBus. Ein Weg aus dieser Misere, wenigstens für den Pentium, will LSI bieten. LSI legt den MPI-Bus als Standard vor. MPI soll das Low-End für den (zukünftigen) Normaluser stellen. Maximal 4 Pentiums finden auf diesem 32/64 Bit-Bus Platz. Generell ist er genau auf dessen Architektur zugeschnitten, also 64 Bit Daten-, 32 Bit Adressbus, Interne MESI Nutzung, 30 oder 33,3Mhz Bustakt (Maximale Bandbreite bei 33Mhz 267 MByte/s). Alle Bussysteme sollen per Bridge unterstützt werden, wobei PCI der Basisbus ist. LSI will jetzt mit der Auslieferung des Chipsatzes der auf den Namen HT354 (Cache Controller), HT355 (Memory Controller), HT 352 (Bus Controller) und HT353 (PCI to EISA-Bridge Controller) beginnen. Alles in allem eine begrüßenswerte Initiative, denn somit ist nicht mehr alleine der Hersteller des MP-Systemes Anbieter der CPU-Karten. Auch eine Mischbestückung ist denkbar.
Et voila, la fin!
—————–
Das war sie, die fast 450 Zeilige MP-Mail. Ich hoffe Ihr seid jetzt etwas schlauer, was MP angeht und lasst Euch einen ATARI Falcon nicht mehr als MP-System andrehen 🙂 Ich denke das es die letzte große Mail vor Weihnachten ist, und zudem habe ich gerade vernommen, daß die 7*up (meine Box) sich aus dem LightNet verabschiedet (nein, ich kenne die Gründe auch nicht) und ich mir für dieses Brett also eine neue Box suchen muß :-((
mfg AXEL